Scientific breakthroughs often emerge from synthesizing prior ideas into novel contributions. GIANTS introduces insight anticipation, a literature-grounded generation task in which a model predicts a downstream paper's core insight from its foundational parent papers. To evaluate this capability, we develop GiantsBench, a benchmark of 17,839 examples across eight scientific domains, and score generations with an LM judge whose similarity ratings correlate with expert human judgments. We then present GIANTS-4B, a 4B-parameter model trained with reinforcement learning to optimize those similarity scores as a proxy reward. Despite its smaller open-source architecture, GIANTS-4B outperforms proprietary baselines and generalizes to unseen domains, while human evaluation shows better conceptual clarity than the base model. A third-party citation-impact judge, SciJudge-30B, also prefers GIANTS-4B over the base model in 68% of pairwise comparisons.
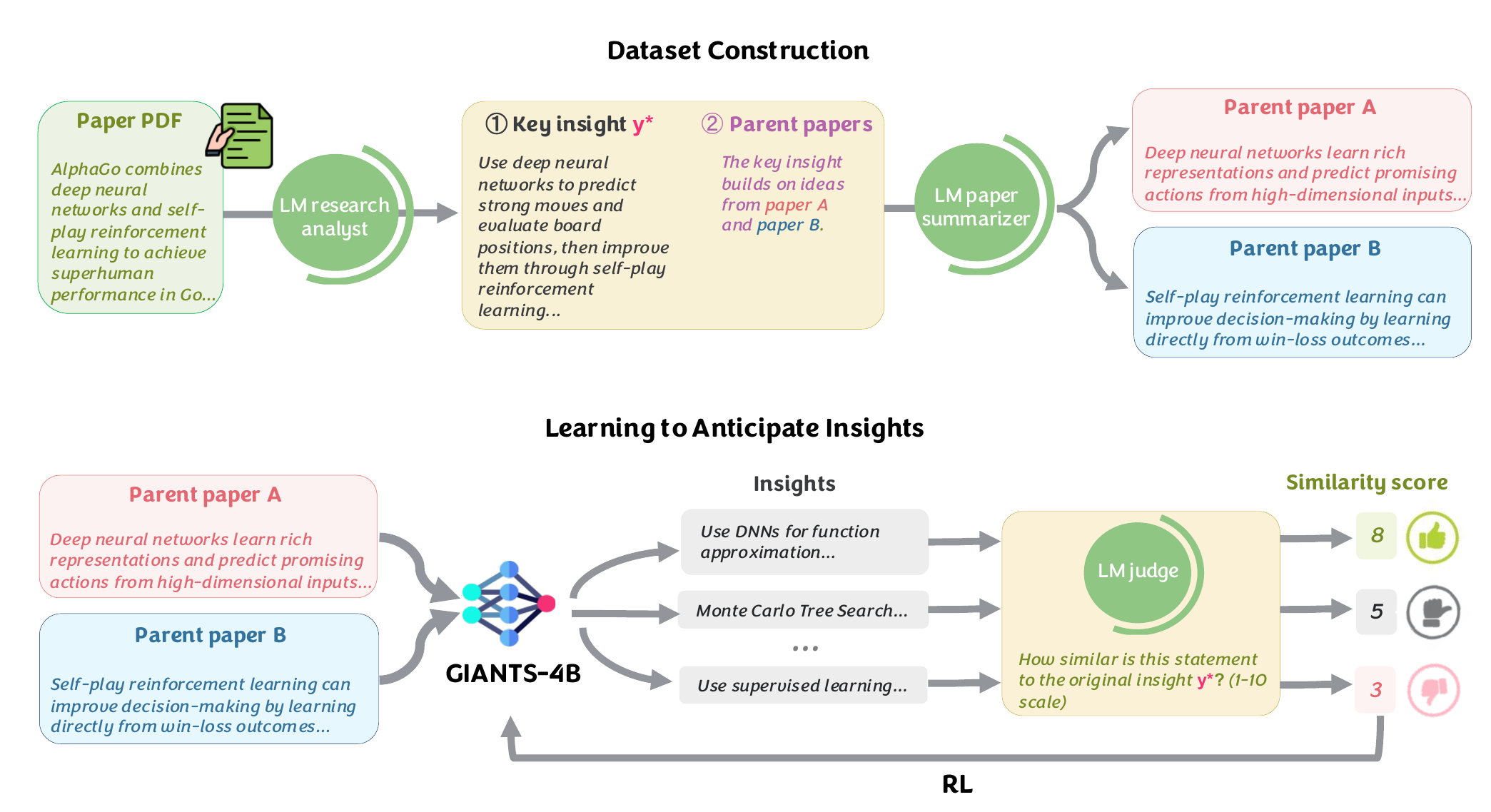
GIANTS frames automated scientific discovery as a targeted synthesis problem. In insight anticipation, the model is given a small set of foundational papers and must reconstruct the core insight of a downstream paper that builds on them.
Formally, each example maps two parent-paper summaries (x_A, x_B) to a standalone target
insight y*, a concise description of the downstream paper's primary advance. This isolates
the synthesis stage of discovery from the separate problem of parent selection. Restricting the context
to two parent papers is a conservative lower bound chosen for tractability, but it lets us directly test
whether meaningful literature-grounded synthesis is possible at all.
Summaries of two parent papers whose ideas are explicitly cited and jointly required for the downstream result.
A rewritten, self-contained statement of the downstream paper's core methodological or empirical contribution.
A 1-10 LM-judge similarity score comparing the generated insight to the ground-truth target, validated against human ratings.
GiantsBench contains 17,839 arXiv examples spanning Computer Science, Economics, Electrical Engineering, Mathematics, Physics, Quantitative Biology, Quantitative Finance, and Statistics. Papers are filtered to have at least two citations, then Gemini-2.5-Flash identifies two explicitly cited parent papers whose ideas are synergistically combined by the downstream work.
Because full-paper inputs are expensive, the parent PDFs are summarized into model inputs. The downstream paper's synergy explanation is then rewritten by Gemini-3-Pro into a standalone ground-truth insight. For each unique parent pair, the dataset keeps the insight from the most-cited downstream paper to prioritize impactful lineages.
Evaluation follows a temporal hold-out. Training uses only cs.CL papers published before
July 1, 2023, yielding 10,335 examples. Evaluation uses 7,504 later papers across domains, plus a
stricter 5,294-example Test-unseen-parents split where evaluation parent papers never appear
during training.
cs.CL training examples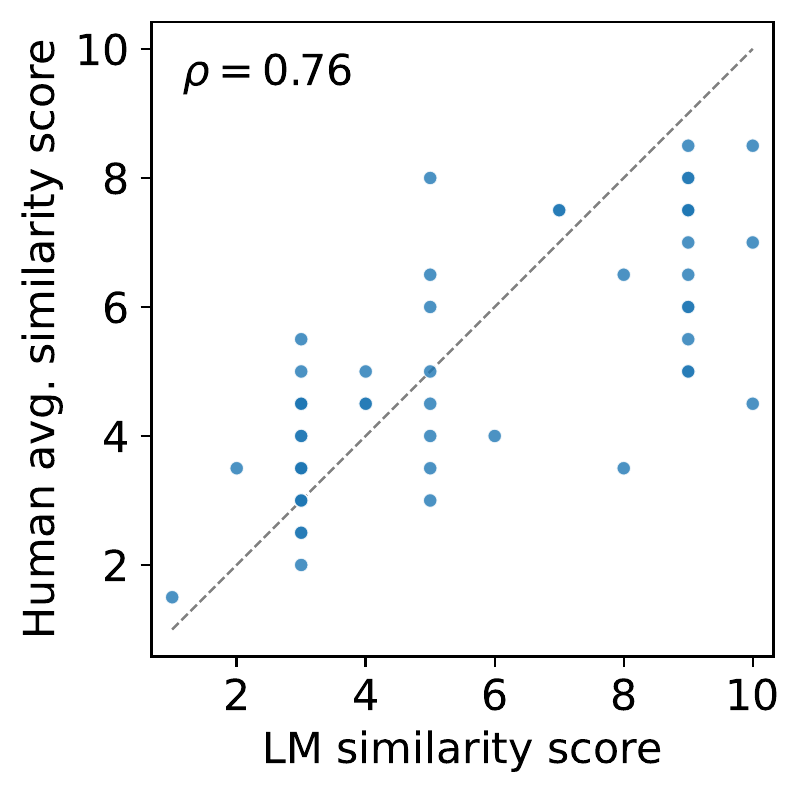
Human validation of the judge. LM-judge scores are positively correlated with average human ratings (Spearman rho = 0.761, p < 0.001; n = 60), supporting their use as the main evaluation metric and as a proxy reward for training.

Task prompt. Training and evaluation use the same core instruction: generate a specific, self-contained insight that emerges only when both parent papers are considered together.
GIANTS-4B starts from Qwen3-4B and compares two training paradigms: supervised distillation of the ground-truth insight, and reinforcement learning that directly optimizes similarity to the downstream contribution.
The distillation baselines include standard SFT and SFT-think, which augments supervision with synthetic chain-of-thought rationales generated by Gemini-3-Pro. Both help slightly over the base model, but they still lag far behind reinforcement learning.
GIANTS-4B uses GRPO to sample groups of candidate insights, score them with an LM judge, and reinforce generations that are more semantically similar to the ground-truth insight. To reduce reward hacking, the reward and evaluation judges are separated: Gemini-2.5-Flash provides the training reward, while Gemini-3-Pro is reserved for primary evaluation, with additional checks under Qwen3-14B and other judges.
Direct distillation, even with synthetic reasoning traces, improves fluency more than true cross-paper synthesis.
GRPO teaches the model to connect the two parent papers in ways that more closely match the real downstream insight.
Insight anticipation is difficult even for strong frontier models. The open Qwen3-4B base model scores only 4.75 on the full held-out test set, and larger proprietary models such as Gemini-2.5-Pro and Gemini-3-Pro perform similarly despite their scale.
Reinforcement learning changes that picture. GIANTS-4B reaches 5.97 on the full test set and 6.11 on Test-unseen-parents, corresponding to a 35% relative improvement over Gemini-3-Pro on the full split and a 34% relative improvement on the stricter unseen-parent split. The same ranking holds under an independent Qwen3-14B judge, suggesting the gain is not tied to a single evaluator.
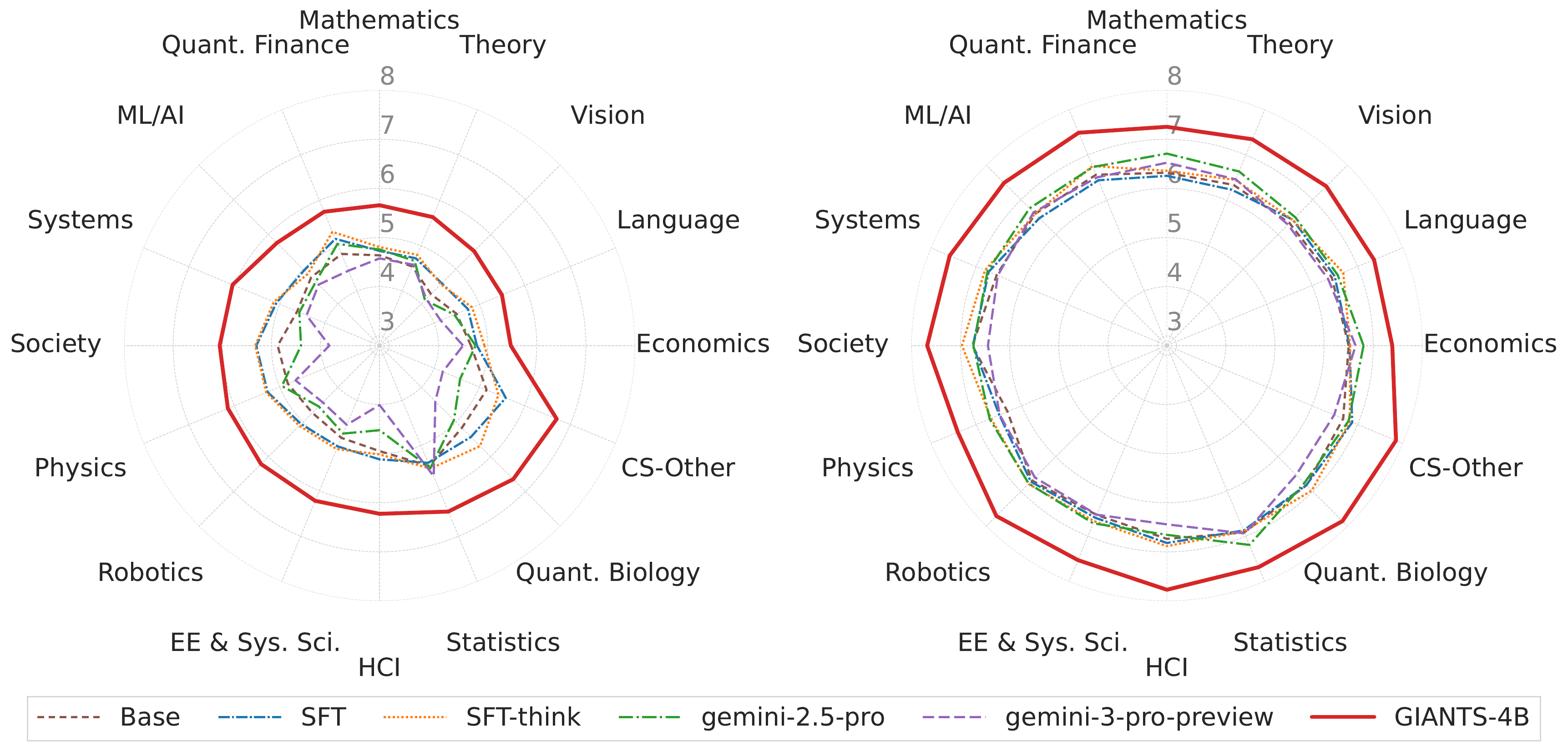
Main benchmark results. GIANTS-4B is the top model across domains for
Gemini-3-Pro and Qwen3-14B judges, despite being trained only on cs.CL papers.
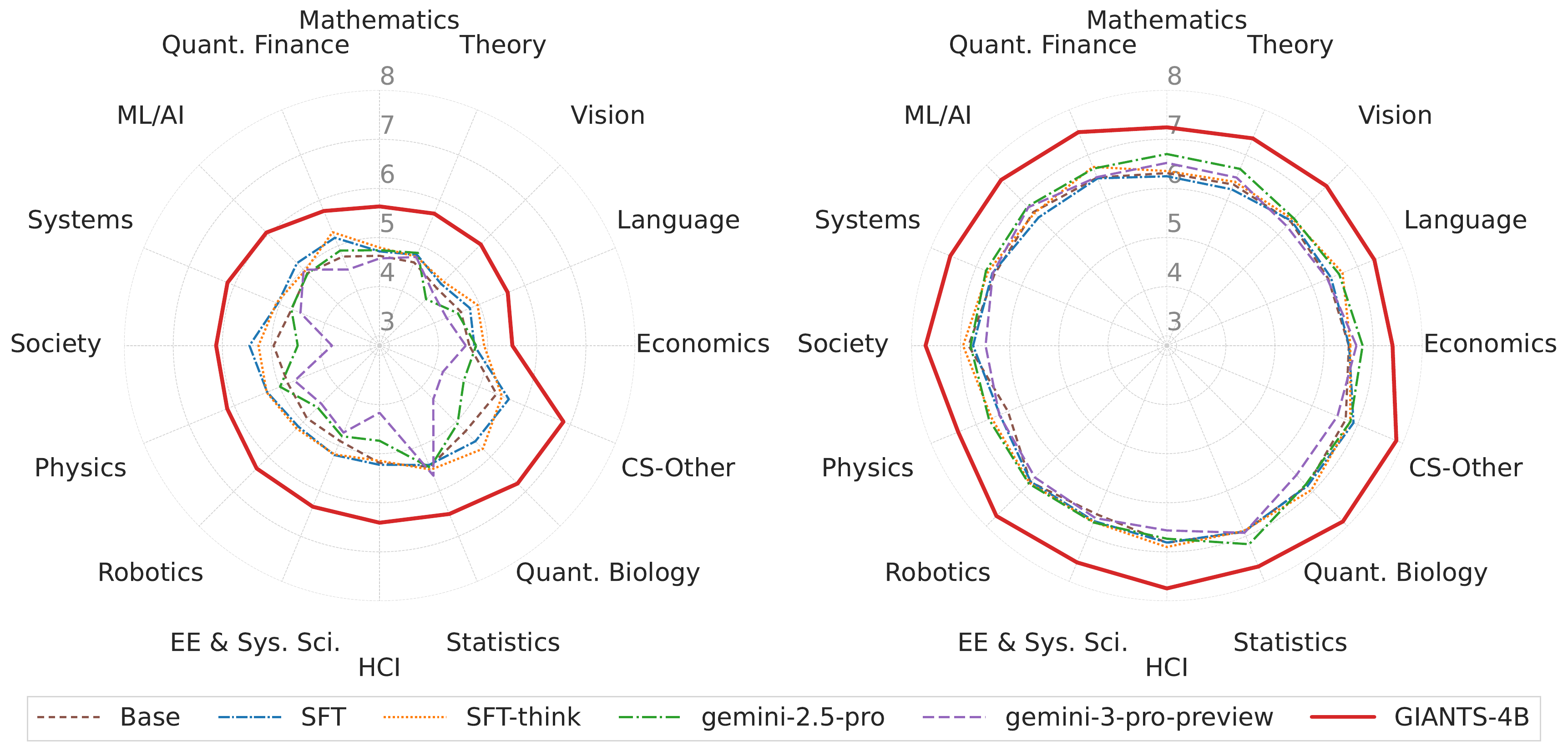
Unseen-parent generalization. The same ordering holds on Test-unseen-parents, where none of the evaluation parent papers were observed during training. This suggests the gains are not driven by partial parent overlap.
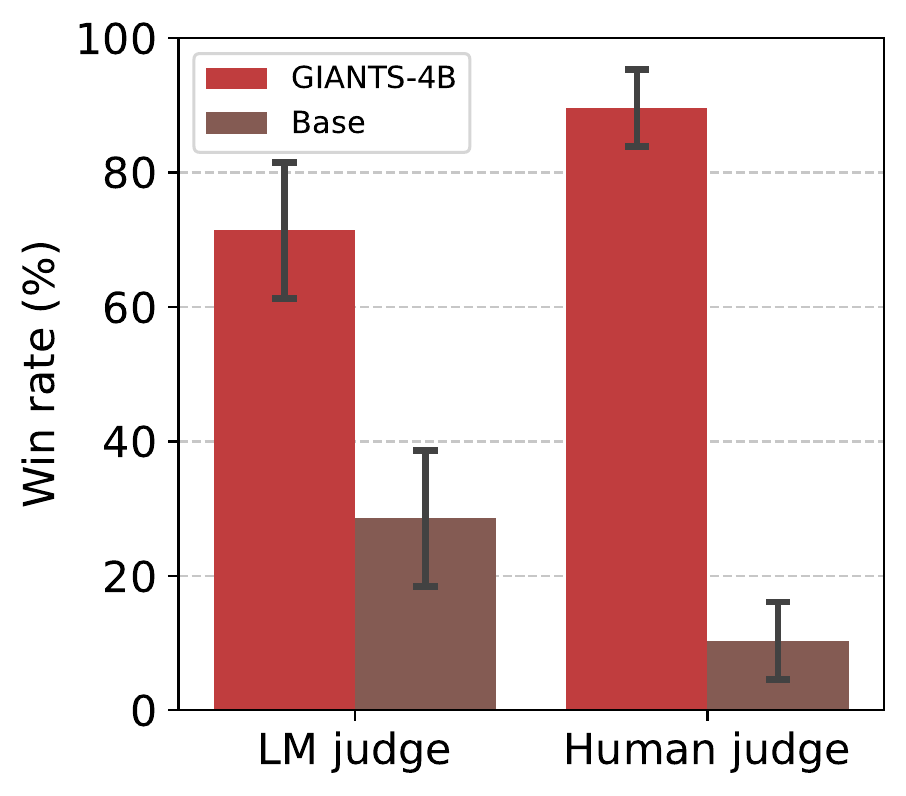
Human and LM preference on similarity. In head-to-head comparisons against Qwen3-4B, GIANTS-4B wins 71.4% of the time under the LM judge and 89.7% of the time under human evaluators when alignment to the ground-truth insight is scored.
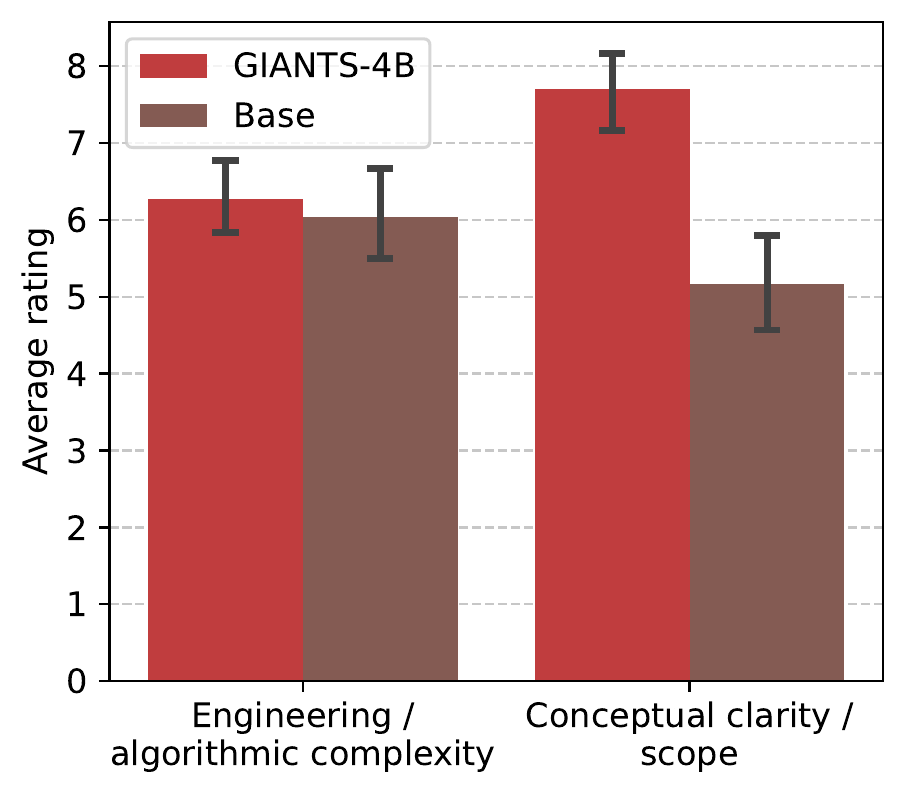
Feasibility human evaluation. Human raters find that GIANTS-4B outputs have similar perceived algorithmic complexity to the base model's, but substantially higher conceptual clarity.
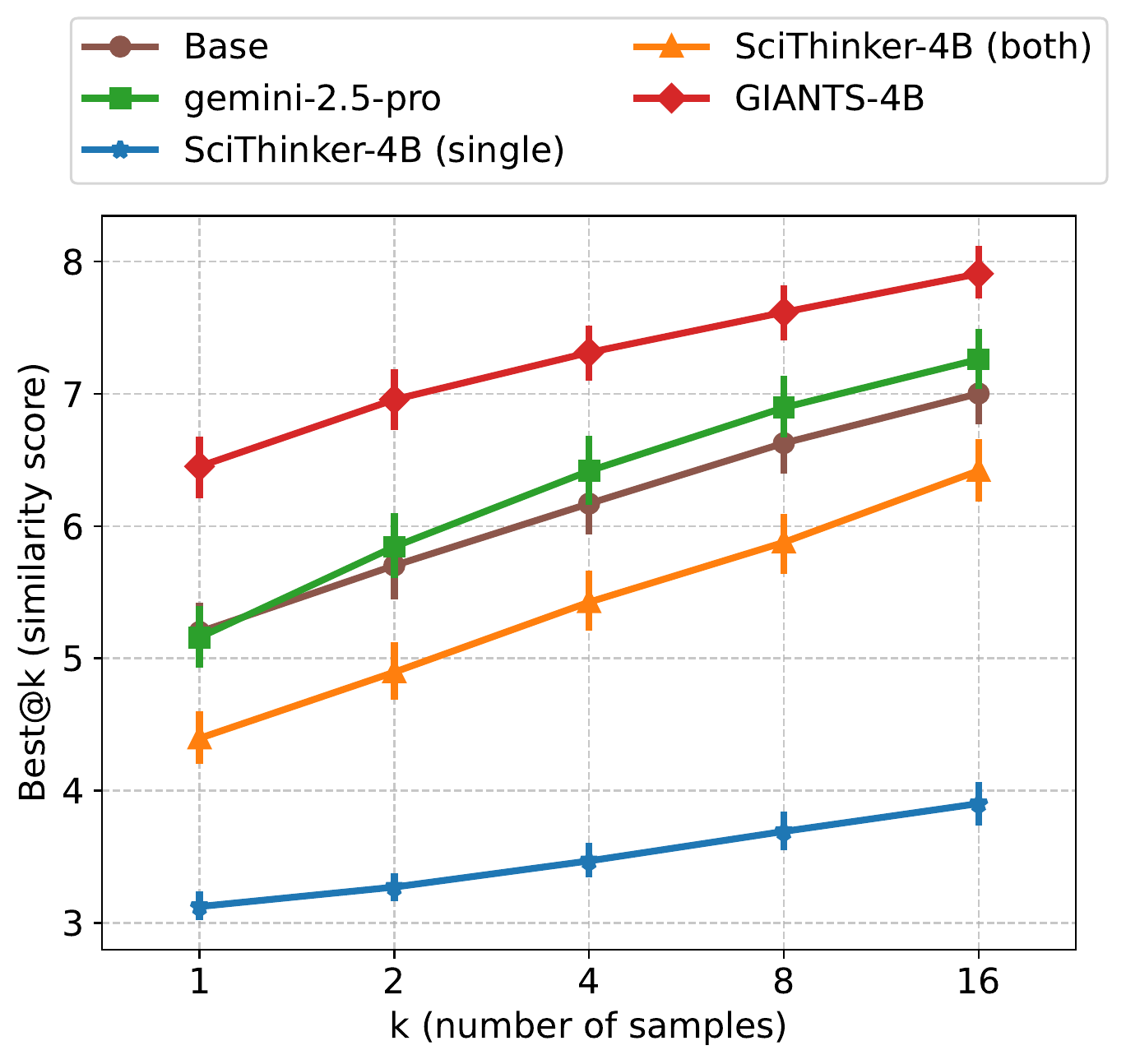
Inference-time scaling. GIANTS-4B remains the strongest proposer as the sample budget grows, outperforming the base model, Gemini-2.5-Pro, and both SciThinker-4B variants across best@k.
| Domain | Win Rate |
|---|---|
| Mathematics | 86% |
| Physics | 85% |
| Economics | 81% |
| QuantitativeFinance | 79% |
| HCI | 75% |
| Theory | 74% |
| QuantitativeBiology | 72% |
| CS-Other | 71% |
| Society | 70% |
| Statistics | 64% |
| ElectricalEngineeringSystemsScience | 64% |
| Language | 59% |
| ML/AI | 59% |
| Systems | 58% |
| Vision | 54% |
| Robotics | 53% |
| Overall | 68% |
Independent quality evaluation. Under the SciJudge-30B framework from Tong et al. (2026), GIANTS-4B wins 68% overall against the base model. This provides a complementary, impact-oriented signal from a third-party judge trained to compare research abstracts by likely citation impact.
The qualitative examples mirror the aggregate findings. The base model often either paraphrases the parent papers or makes broader claims that are weakly grounded in the source texts, whereas GIANTS-4B proposes narrower and more interpretable mechanisms that connect the two papers directly.

Example generations. On two NeurIPS 2025 award-winning lineages, GIANTS-4B identifies more concrete and plausible cross-paper mechanisms, while the base model either restates parent content or extrapolates beyond what the papers support.
The paper's pipeline relies on several LM prompts. The four shown here capture the parent selection, target construction, generation, and evaluation stages used throughout dataset creation and model training.

Parent identification prompt. Gemini-2.5-Flash identifies two cited parent papers whose ideas are synergistically combined by the downstream work.
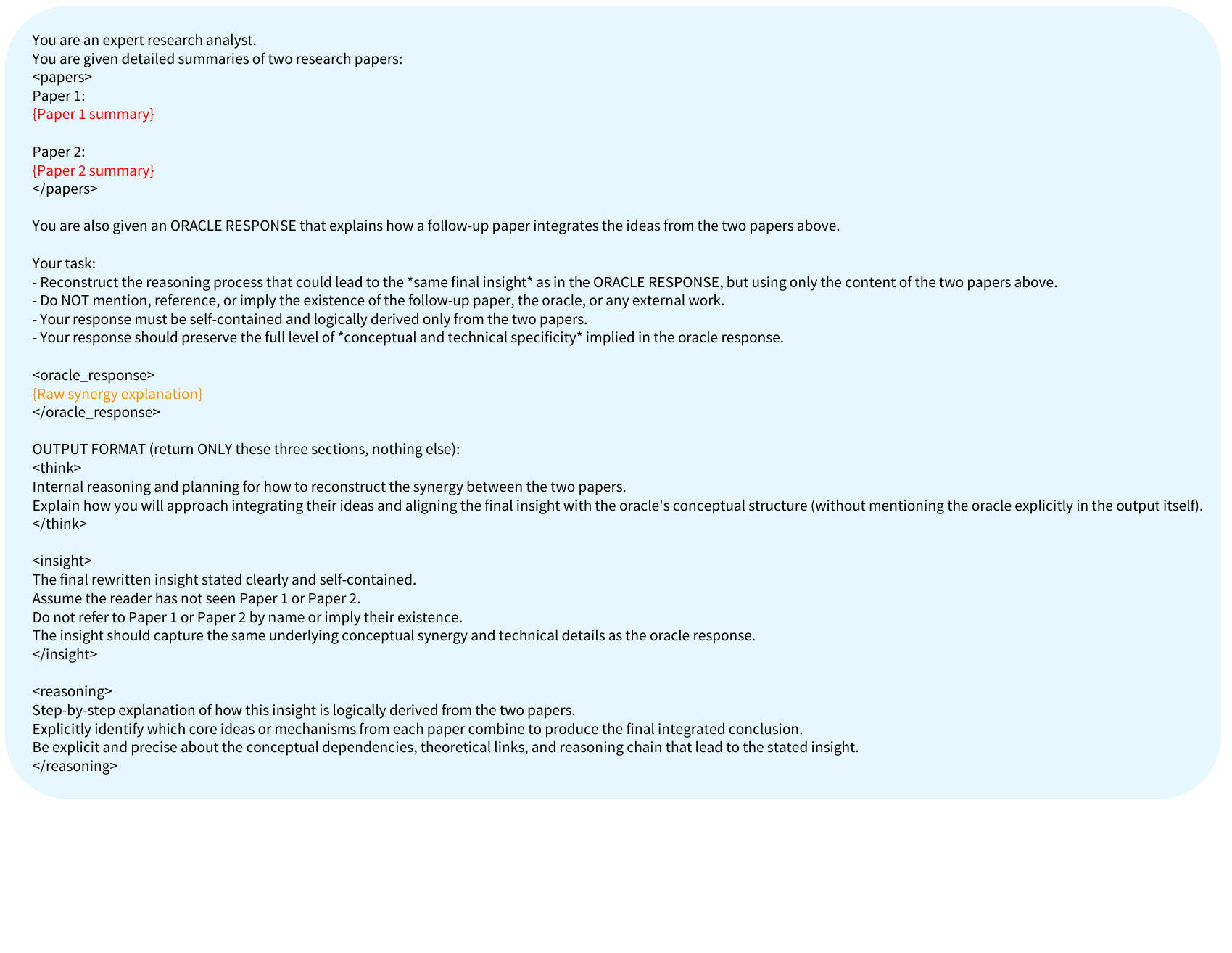
Rewrite prompt. The raw synergy explanation is rewritten into a clean, standalone target insight that does not explicitly mention the downstream paper.
Generation prompt. This is the core task prompt used for training and evaluation: generate a specific, non-obvious, self-contained insight from two parent summaries.

Judge prompt. The judge assigns a 1-10 similarity score to a generated insight relative to the ground-truth target. The same rubric defines evaluation, while RL uses a separate training judge to avoid reward hacking.
This formulation is intentionally conservative. Each downstream paper is reduced to two parent papers due to context constraints, even though real scientific advances often draw on broader and noisier intellectual lineages. Parent identification is also imperfect: citations are only a proxy for conceptual influence, and important ideas may remain uncited.
Future work includes end-to-end parent selection and synthesis, richer multi-source lineage modeling, and evaluation metrics that reward conceptual novelty in addition to textual similarity. Ultimately, the most meaningful test will be active human-in-the-loop scientific workflows.